Introduction
The Dogma
mRNA
The 3 Secrets of mRNA/DNA
tRNA (Transfer RNA)
Introduction
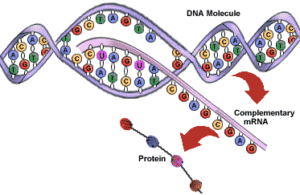
Having already covered the basics of DNA, let’s turn our attention to the principles which govern what actually happens to DNA and how this results in life being the way it is!
The Dogma
DNA is a large molecule made up of variable bases (adenine, thymine, cytosine, guanine). The precise sequence and location of these bases determines what structure a second molecule, mRNA (messenger RNA) has once it’s “read” the template DNA. In turn, the sequence and location of mRNA bases determines what amino acids will be chosen in the assembly of a given protein that the original DNA encoded for, once it reaches a ribosome and is constructed by tRNA (transfer RNA).
mRNA
mRNA stands for messenger ribonucleic acid. DNA is deoxyribonucleic acid, and the only difference really is in the sugar in the backbone. A more important difference is that mRNA is single-stranded unlike double-stranded DNA. Additionally, instead of the base thymine, mRNA uses uracil. So while adenine pairs up with thymine in DNA, it pairs up with uracil in mRNA. Knowing that, the mRNA derived from this DNA (looking at the top strand) would be as follows:
DNA: ATGGGTACAAATGC (top strand)
TACCCATGTTTACG (bottom strand)
mRNA: AUGGGUACAAAUGC (single strand)
As you can see, both the top DNA strand and the mRNA are complementary to the bottom DNA strand (in reality either top or bottom may be read, but for simplicity we only look at the top strand whenever it’s given – we assume that is the gene of interest). Therefore the top strand may be called the coding strand (or sense strand) while the bottom is the template strand (or anti-sense strand). It’s called template because it’s the bit of DNA used to actually build up the mRNA according to. The result? The coding strand of DNA except that T is replaced by U!