DNA structure
What are the strands made of?
DNA replication
The genetic code
mRNA
mRNA / DNA
tRNA (Transfer RNA)
Protein synthesis
Transcription
Splicing
Translation
Cause of Mutations
The Effects of Mutations
DNA structure
DNA (deoxyribonucleic acid) is a large molecule which carries the genetic information, or blueprint, of all life on Earth. Mutations arising in the DNA code account for the diversity upon which evolution by natural selection can work. Therefore, it is not far-fetched to say that DNA is one of the central, most important molecules in living organisms.
For such an important molecule, it sure looks beautiful:

What are the strands made of?
The strands are made of repeating units consisting of a deoxyribose (sugar) molecule with a phosphate molecule attached to it; hence, it is called a sugar-phosphate backbone.
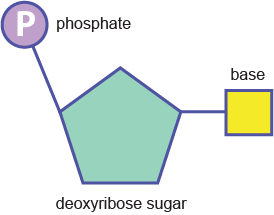
DNA is a double helix i.e. two individual strands running along each other in an anti-parallel way, connected to one another by relatively weak hydrogen bonds. DNA’s structure can be learned easily by thinking about the strands and the “stuff in-between” separately.
Phosphodiester bonds between nucleotides (above) create the backbone:
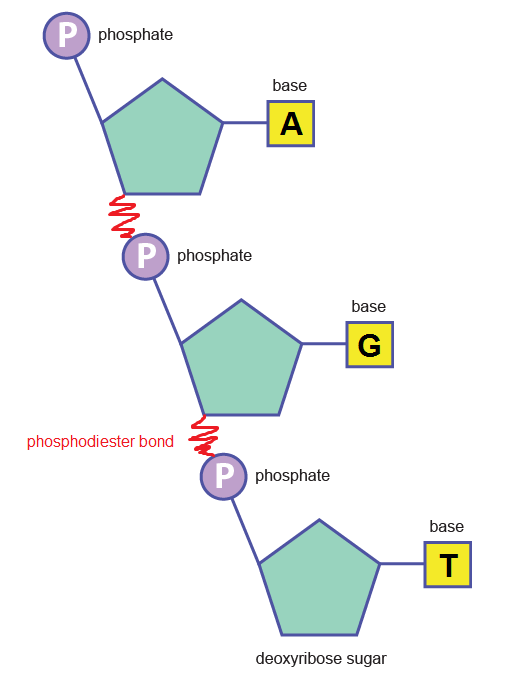
What is the centre made of?
Attached to the sugar molecules in the backbone are a different type of molecule called nitrogenous base. There are 4 bases in DNA: adenine, thymine, cytosine and guanine. These are abbreviated by their initials: A, T, C and G….