The method
The literature
The ethics
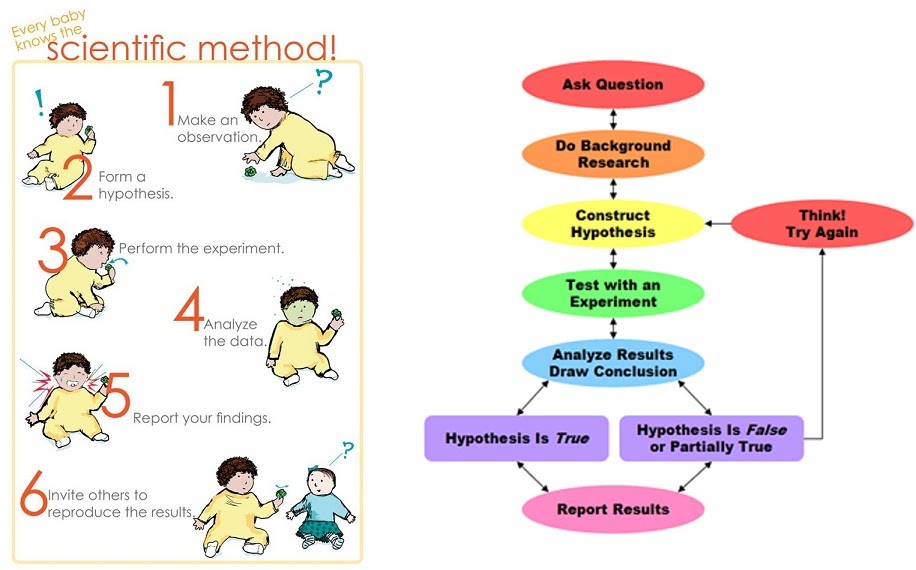
Obtaining results is the next step. This involves first collecting the data which as previously mentioned, might start right from the experimental design step because sometimes the data might be missed unless specifically waited on to be collected. Sometimes an experimenter might have a split second to collect the data, else the experiment is wasted. This must be planned for in advance. Sometimes equipment collects data automatically in which case one can take a nap.
Either way, once collected, data is kept in a store (whether physical or digital) as raw data. This is then looked at and analysed using various methods such as computing, graph generator software, image processors, etc.
Evaluation of results involves fitting the new data into the existing knowledge. Sometimes this involves discarding what is outlier data, running additional statistical tests to fine tune results, dealing with unexpected results, or outright finding out that the experiment didn’t run as intended.
This feeds into the last step of drawing conclusions and using them to inform the start of a new cycle with a new testable hypothesis. It may be that the failed experiment will be carried out again; a slight variation of the experiment will be carried out again; a different experiment will be carried out; the results support rejecting or accepting the null hypothesis, and a new area of the field can be created with new experiments; the hypothesis is settled and the area is abandoned or paused in the pursuit of a different area of the field; or indeed, the findings break new ground, spawn new directions of research, and inspire innovation, business and citizen interest and application of the new knowledge.
The literature
As you can see, data regarding something like climate change comes in many different forms and from many different sources obtained in many different ways, so curating it all together in a specific field or to answer one question is…