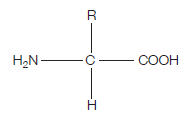
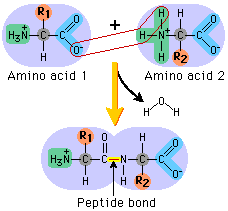
If you’re wondering what this actually is, read on. The clues are in the name (as they usually are). AMINO – the H2N on the left hand side is an amino group ACID – the COOH on the right hand side is a carboxylic acid group (simply an acid) The hydrogen (H) on the bottom is there all the time (just like the amino group and the acid group), while the R group is the variable which determines what particular amino acid this will be. For example, if the R group was a hydrogen, the amino acid would be glycine. The next diagram shows condensation, and the subsequent formation of a bond between two amino acids (any two). This bond is a peptide bond. The resulting molecule is called a polypeptide.
This video is an excellent tool for understanding the processes by which these amino acids end up in highly structured, complex proteins with varied and important functions within organisms:
The theme of protein structure versus function is really strongly played on in exams, throughout Advanced/Higher biology. The core idea must be learnt, and this is it:
Proteins have a primary, secondary, tertiary and (some only) quaternary structure.
Protein primary structure is simply the sequence of amino acids in the polypeptide, while secondary structure refers to the conformation of the polypeptide. This can be an alpha helix, a parallel/anti-parallel beta sheet, or a turn.
The tertiary structure of proteins is their 3D shape which is highly folded and has a unique structure. This structure gives proteins their specific function. For example, if insulin was misfolded, it would cease to function properly. Of course though, the origin of misfolding is likely to be in the primary structure, due to a mutation.
For example, if the gene responsible for coding the amino acid sequence for insulin was mutated, then the insulin’s primary structure (which is the string of amino acids) would be different, leading to a different secondary structure, tertiary structure, and ultimately, a lack of proper function….