What is the structure of DNA and RNA?
Deoxyribonucleic Acid and Ribonucleic Acid
A-T and G-T
Uracil
Tips
What is the structure of DNA and RNA?
DNA and RNA are key carriers of biological information. For example, DNA may store a gene coding for haemoglobin or insulin, which is then processed by RNA and ribosomes (which are sophisticated machines themselves made of RNA and proteins) to manufacture those proteins. Both DNA and RNA are nucleic acids (that’s the “NA” part of their acronym). They also contain a sugar group of a 5-carbon ring called a pentose. In DNA this is deoxyribose, while in RNA it’s ribose. This completes their respective names: deoxyribonucleic acid and ribonucleic acid. The monomers of these nucleic acid compounds are nucleotides. Aside from the nitrogen-containing base and the pentose, they contain a phosphate group.
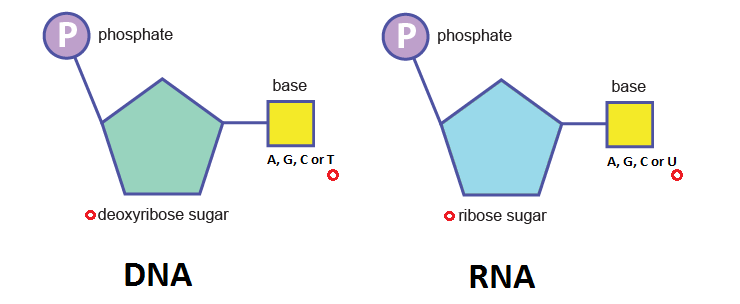
As you can see, the nitrogenous base in the DNA nucleotide is one of four options: adenine, guanine, cytosine or thymine . RNA has thymine switched for uracil, making its base options adenine, guanine, cytosine or uracil. To form the DNA or RNA polymer, these nucleotide monomers join together via a condensation reaction which produces a phosphodiester bond .
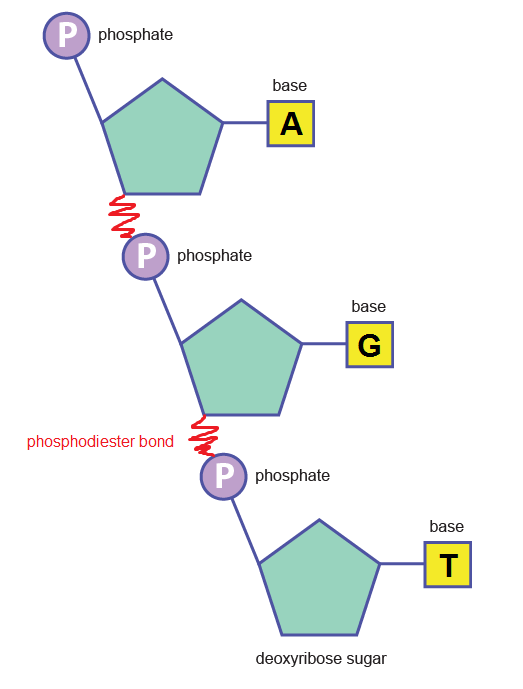
Starting to look a bit familiar? This is just a small section of what would be a much longer DNA polynucleotide chain. Put two of them together in a double helical fashion, kept together by hydrogen bonds between the two strands, and voilà ! we have ourselves a DNA molecule.
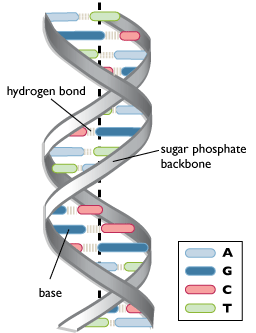
As you can see, the base pairings are A–T and G–C. They follow this pairing rule and thus are known as complementary bases. Therefore, if the number of adenine bases were known, the number of thymine bases would be easy to deduce (equal to the number of adenine bases) as well as that of guanine/cytosine bases (total number of bases – adenine – thymine = guanine + cytosine; divided in half equals either the number of guanine bases or that of cytosine bases as they are equal).
RNA on the other hand does not follow the same complex overall polynucleotide structure as that of the DNA double helix, and is instead a relatively short, single strand of nucleotides – perhaps like the one depicted above with the phosphodiester bond labelled (a trimer)! Except…..