The structure of the Genome Translation
Non-coding DNA
LINEs (long interspersed nuclear elements)
Introduction
As previously touched on, the genome is the entirety of genetic material carried by an individual or species and varies accordingly. The database of genomes of different species is growing and includes humans (the Human Genome Project). For example, the human genome, by chromosome, is viewable here: https://www.ncbi.nlm.nih.gov/genome/?term=homo+sapiens
A minority of the genetic material that is DNA actually encodes amino acids to make proteins. Wherever a DNA sequence in a genome does this, it is called a gene. The vast majority of DNA in humans, for example, does not consist of genes.
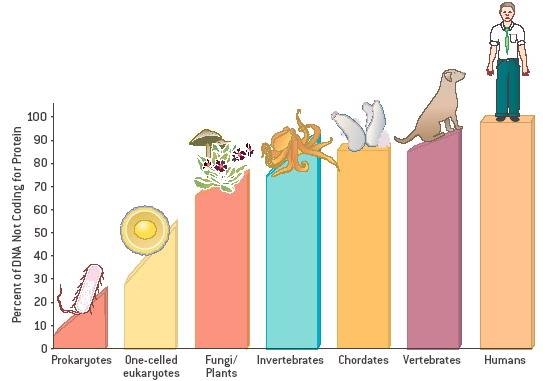
The rest of the DNA has functions in making RNA, some of which isn’t used as mRNA to make proteins via translation, but has other functions such as tRNA which carries out translation alongside ribosomes and mRNA, and rRNA (ribosomal RNA) that makes up ribosomes.
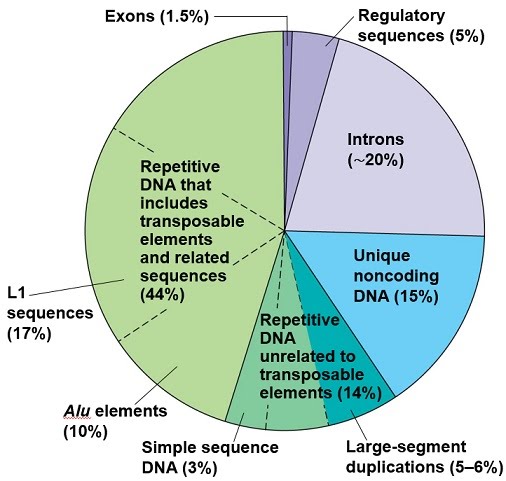
There’s also a whole load of other non-coding DNA that just repeats itself a million times and even bits that jump around within the genome (transposable elements, TEs). Some non-coding DNA is involved in regulation of transcription, while other non-coding DNA is just there not taking active part in any obvious way, or perhaps waiting to be discovered sometime soon!
Surprisingly, as little as 1.5% of the human genome is used in the production of proteins – these are the exons that get joined following mRNA splicing to remove the introns, before heading out to the ribosome for translation. Some of the repetitive sequences are very short, while others are quite long. For perspective, the human insulin gene is almost 5,000 DNA base pairs (5 kbp) long, while the whole genome is 3,234,830,000 base pairs (3.23 Gbp) long.
Within the repetitive sequences including TEs, there are subtypes of elements such as Alu elements, so called because they are short DNA sequences that enzymes from the bacterium Arthrobacter luteus recognise………