Introduction
The Dogma
mRNA
The 3 Secrets of mRNA/DNA
tRNA (Transfer RNA)
Non-coding DNA
Introduction
DNA and chromosomes may seem like completely separate things. Well, they’re not. In fact, all chromosomes are individual DNA molecules coiled and twisted around, because DNA is huge. At least in eukaryotes it is. That’s one of the first differences between eukaryotes and prokaryotes in their DNA – prokaryotes have less DNA.
Eukaryotic DNA is stored within the nucleus of each cell (apart from cells without one, e.g. red blood cells). Because of its sheer size, it must be organised well. Proteins called histones help do just that:
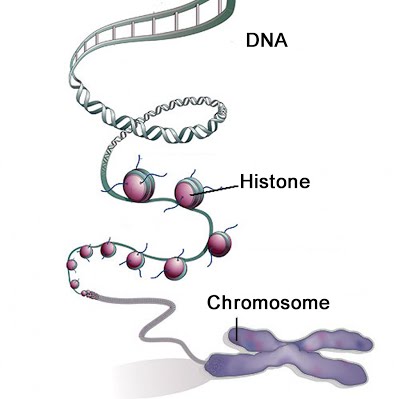
In eukaryotes, mitochondria and chloroplasts have their own DNA. Similarly to prokaryotes, this organelle DNA is short, circular and not associated with proteins.
Having already covered the basics of DNA, let’s turn our attention to the principles which govern what actually happens to DNA and how this results in life being the way it is!
The Dogma
DNA is a large molecule made up of variable bases (adenine, thymine, cytosine, guanine). The precise sequence and location of these bases determines what structure a second molecule, mRNA (messenger RNA) has once it’s “read” the template DNA. In turn, the sequence and location of mRNA bases determines what amino acids will be chosen in the assembly of a given protein that the original DNA encoded for, once it reaches a ribosome and is constructed by tRNA (transfer RNA).
DNA can also code for ribosomal RNA which makes up..